Linux에서 awk 명령을 사용하는 방법

Linux에서는 awk명령 줄 텍스트 조작 발전기이자 강력한 스크립팅 언어입니다. 다음은 가장 멋진 기능 중 일부를 소개합니다.
awk가 그 이름을 얻은 방법
이 awk 명령은 1977 년 원본 버전을 작성한 세 사람인 Alfred Aho, Peter Weinberger 및 Brian Kernighan의 이니셜을 사용하여 명명되었습니다. 이 세 사람은 전설적인 AT & T Bell Laboratories Unix 판테온 출신입니다. 그 이후로 다른 많은 사람들의 공헌으로 awk 계속 진화하고 있습니다.
완전한 스크립팅 언어이자 명령 줄을위한 완전한 텍스트 조작 툴킷입니다. 이 기사가 식욕을 돋우는 경우에 대한 모든 세부 사항 awk 과 기능을 확인할 수 있습니다 .
규칙, 패턴 및 작업
awk패턴과 동작으로 구성된 규칙을 포함하는 프로그램에서 작동합니다. 패턴과 일치하는 텍스트에서 작업이 실행됩니다. 패턴은 중괄호 ( {}) 로 묶여 있습니다. 패턴과 행동이 함께 규칙을 형성합니다. 전체 awk프로그램은 작은 따옴표 ( ')로 묶여 있습니다.
가장 간단한 유형의 awk프로그램을 살펴 보겠습니다 . 패턴이 없으므로 입력 된 모든 텍스트 행과 일치합니다. 즉, 모든 행에서 작업이 실행됩니다. who명령 의 출력에 사용합니다 .
다음은 표준 출력입니다 who.
WHO

아마도 우리는 그 모든 정보가 필요하지는 않지만, 단지 계정의 이름을보고 싶을 것입니다. 출력을 who로 파이프 awk한 다음 awk첫 번째 필드 만 인쇄하도록 지시 할 수 있습니다.
기본적 awk으로 필드는 공백으로 둘러싸인 문자열, 줄의 시작 또는 줄의 끝으로 간주됩니다. 필드는 달러 기호 ( $)와 숫자 로 식별됩니다 . 따라서 $1첫 번째 필드 print 를 인쇄하기 위해 액션 과 함께 사용할 첫 번째 필드를 나타냅니다 .
다음을 입력합니다.
누가 | awk '{print $ 1}'
awk 첫 번째 필드를 인쇄하고 나머지 줄을 버립니다.
원하는만큼 필드를 인쇄 할 수 있습니다. 쉼표를 구분 기호로 추가하면 awk각 필드 사이에 공백을 인쇄합니다.
다음을 입력하여 사용자가 로그인 한 시간도 인쇄합니다 (필드 4).
누가 | awk '{print $ 1, $ 4}'
몇 가지 특수 필드 식별자가 있습니다. 다음은 전체 텍스트 줄과 텍스트 줄의 마지막 필드를 나타냅니다.
- $ 0 : 전체 텍스트 줄을 나타냅니다.
- $ 1 : 첫 번째 필드를 나타냅니다.
- $ 2 : 두 번째 필드를 나타냅니다.
- $ 7 : 일곱 번째 필드를 나타냅니다.
- $ 45 : 45 번째 필드를 나타냅니다.
- $ NF : "필드 수"를 나타내며 마지막 필드를 나타냅니다.
다음을 입력하여 Dennis Ritchie의 짧은 따옴표가 포함 된 작은 텍스트 파일을 가져옵니다.
고양이 dennis_ritchie.txt

awk견적의 첫 번째, 두 번째 및 마지막 필드를 인쇄 하려고 합니다. 터미널 창에 둘러싸여 있지만 텍스트 한 줄에 불과합니다.
다음 명령을 입력합니다.
awk '{print $ 1, $ 2, $ NF}'dennis_ritchie.txt
우리는 그 "단순함"을 모릅니다. 텍스트 줄의 18 번째 필드이므로 상관하지 않습니다. 우리가 아는 것은 이것이 마지막 필드이고 $NF그 값을 얻기 위해 사용할 수 있다는 것 입니다. 기간은 필드 본문에서 다른 문자로 간주됩니다.
출력 필드 구분자 추가
awk기본 공백 문자 대신 필드 사이에 특정 문자를 인쇄하도록 지시 할 수도 있습니다 . date명령 의 기본 출력 은 시간이 바로 중간에 있기 때문에 약간 특이합니다. 그러나 다음을 입력하고 awk원하는 필드를 추출하는 데 사용할 수 있습니다 .
데이트
날짜 | awk '{print $ 2, $ 3, $ 6}'
우리는 사용합니다 OFS 월, 일, 년 사이에 구분 기호를 넣어 (출력 필드 분리) 변수를. 아래에서 명령을 '중괄호 ( {})가 아닌 작은 따옴표 ( )로 묶습니다 .
날짜 | awk 'OFS = "/"{print $ 2, $ 3, $ 6}'날짜 | awk 'OFS = "-"{print $ 2, $ 3, $ 6}'
BEGIN 및 END 규칙
BEGIN규칙은 텍스트 처리가 시작되기 전에 한 번 실행됩니다. 실제로 awk 텍스트를 읽기도 전에 실행 됩니다. END모든 처리가 완료된 후에 규칙을 실행한다. 여러 개의 BEGIN 및 END규칙을 가질 수 있으며 순서대로 실행됩니다.
BEGIN규칙 의 예에서는 dennis_ritchie.txt이전에 사용한 파일 의 전체 인용문을 그 위에 제목과 함께 인쇄 합니다.
이를 위해 다음 명령을 입력합니다.
awk 'BEGIN {print "Dennis Ritchie"} {print $ 0}'dennis_ritchie.txt
메모 BEGIN규정하는 중괄호의 그것의 자신의 세트로 묶여 행동의 그것의 자신의 세트가있다 ( {}).
우리는 우리가에서 파이프 출력 이전에 사용 된 명령에이 같은 기술을 사용할 수 있습니다 who로를 awk. 이를 위해 다음을 입력합니다.
누가 | awk 'BEGIN {print "Active Sessions"} {print $ 1, $ 4}'
입력 필드 구분자
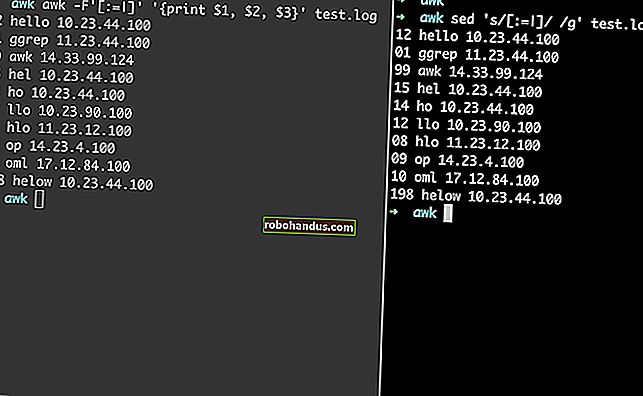
당신이 원하는 경우 awk별도의 필드에 공백을 사용하지 않는 텍스트로 작업하려면, 당신은 문자 필드 구분자로 텍스트 용도를 말할 수 있습니다. 예를 들어 /etc/passwd파일은 콜론 ( :)을 사용하여 필드를 구분합니다.
We’ll use that file and the -F (separator string) option to tell awk to use the colon (:) as the separator. We type the following to tell awk to print the name of the user account and the home folder:
awk -F: '{print $1,$6}' /etc/passwd
The output contains the name of the user account (or application or daemon name) and the home folder (or the location of the application).

Adding Patterns
If all we’re interested in are regular user accounts, we can include a pattern with our print action to filter out all other entries. Because User ID numbers are equal to, or greater than, 1,000, we can base our filter on that information.
We type the following to execute our print action only when the third field ($3) contains a value of 1,000 or greater:
awk -F: '$3 >= 1000 {print $1,$6}' /etc/passwd
The pattern should immediately precede the action with which it’s associated.
We can use the BEGIN rule to provide a title for our little report. We type the following, using the (\n) notation to insert a newline character into the title string:
awk -F: 'BEGIN {print "User Accounts\n-------------"} $3 >= 1000 {print $1,$6}' /etc/passwd
Patterns are full-fledged regular expressions, and they’re one of the glories of awk.
Let’s say we want to see the universally unique identifiers (UUIDs) of the mounted file systems. If we search through the /etc/fstab file for occurrences of the string “UUID,” it ought to return that information for us.
We use the search pattern “/UUID/” in our command:
awk '/UUID/ {print $0}' /etc/fstab
It finds all occurrences of “UUID” and prints those lines. We actually would’ve gotten the same result without the print action because the default action prints the entire line of text. For clarity, though, it’s often useful to be explicit. When you look through a script or your history file, you’ll be glad you left clues for yourself.
The first line found was a comment line, and although the “UUID” string is in the middle of it, awk still found it. We can tweak the regular expression and tell awk to process only lines that start with “UUID.” To do so, we type the following which includes the start of line token (^):
awk '/^UUID/ {print $0}' /etc/fstab
That’s better! Now, we only see genuine mount instructions. To refine the output even further, we type the following and restrict the display to the first field:
awk '/^UUID/ {print $1}' /etc/fstab
If we had multiple file systems mounted on this machine, we’d get a neat table of their UUIDs.
Built-In Functions
awk has many functions you can call and use in your own programs, both from the command line and in scripts. If you do some digging, you’ll find it very fruitful.
To demonstrate the general technique to call a function, we’ll look at some numeric ones. For example, the following prints the square root of 625:
awk 'BEGIN { print sqrt(625)}'This command prints the arctangent of 0 (zero) and -1 (which happens to be the mathematical constant, pi):
awk 'BEGIN {print atan2(0, -1)}'In the following command, we modify the result of the atan2() function before we print it:
awk 'BEGIN {print atan2(0, -1)*100}'Functions can accept expressions as parameters. For example, here’s a convoluted way to ask for the square root of 25:
awk 'BEGIN { print sqrt((2+3)*5)}'
awk Scripts
If your command line gets complicated, or you develop a routine you know you’ll want to use again, you can transfer your awk command into a script.
In our example script, we’re going to do all of the following:
- Tell the shell which executable to use to run the script.
- Prepare
awkto use theFSfield separator variable to read input text with fields separated by colons (:). - Use the
OFSoutput field separator to tellawkto use colons (:) to separate fields in the output. - Set a counter to 0 (zero).
- Set the second field of each line of text to a blank value (it’s always an “x,” so we don’t need to see it).
- Print the line with the modified second field.
- Increment the counter.
- Print the value of the counter.
Our script is shown below.

The BEGIN rule carries out the preparatory steps, while the END rule displays the counter value. The middle rule (which has no name, nor pattern so it matches every line) modifies the second field, prints the line, and increments the counter.
The first line of the script tells the shell which executable to use (awk, in our example) to run the script. It also passes the -f (filename) option to awk, which informs it the text it’s going to process will come from a file. We’ll pass the filename to the script when we run it.
We’ve included the script below as text so you can cut and paste:
#!/usr/bin/awk -f BEGIN { # set the input and output field separators FS=":" OFS=":" # zero the accounts counter accounts=0 } { # set field 2 to nothing $2="" # print the entire line print $0 # count another account accounts++ } END { # print the results print accounts " accounts.\n" }Save this in a file called omit.awk. To make the script executable, we type the following using chmod:
chmod +x omit.awk

Now, we’ll run it and pass the /etc/passwd file to the script. This is the file awk will process for us, using the rules within the script:
./omit.awk /etc/passwd

The file is processed and each line is displayed, as shown below.

The “x” entries in the second field were removed, but note the field separators are still present. The lines are counted and the total is given at the bottom of the output.
awk Doesn’t Stand for Awkward
awk doesn’t stand for awkward; it stands for elegance. It’s been described as a processing filter and a report writer. More accurately, it’s both of these, or, rather, a tool you can use for both of these tasks. In just a few lines, awk achieves what requires extensive coding in a traditional language.
That power is harnessed by the simple concept of rules that contain patterns, that select the text to process, and actions that define the processing.